Missing values can be of two types. The first type is an explicitly missing value - a value that is represented by an empty cell in the table. An example could be the lack of air temperature measurement from a weather station in selected day. In the table we have a row defining the selected station and the date but the cell with temperature is empty.
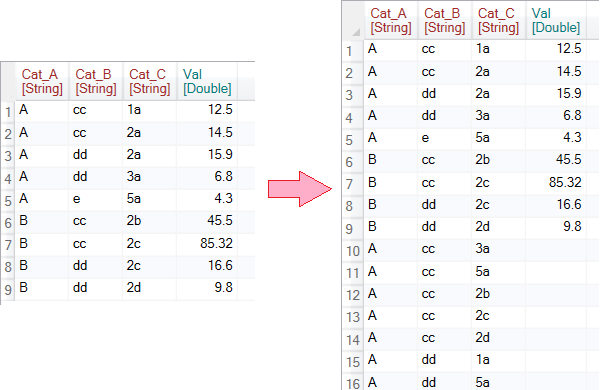
The second type is implicitly missing value.Its example can be found for example in time series of precipitation measurements. If it was not raining on the station that day, we don’t have a record of that day with a value of 0 in the table, but that date (row) us skipped. Another example can be weight measurements for gender and age categories. Each row contains an average values for the selected gender and age range.
In this type of dataset, records are omitted if there is no data. At first glance, we may not even notice such implicitly missing values. Consequently, various process or interpretation errors may occur in the statistical processing of the data or its visualization.
Exactly for this purpose you can use the Complete function. The function makes it easy to transform implicitly missing values into explicit. The function fills in a missing category, a value from a sequence, or a combination of several categorical variables. The remaining columns that are not involved in the processing will be empty and you immediately know that measurements for the for the category are missing. The following video tutorial quickly shows the practical application.
Using the described function is very simple, fast and straightforward. On the other hand, the function makes it possible to create very advanced types of data completion using few parameters. A complete description of all parameters and examples of their use can be found in the documentation. In the next posts we will look at functions of the opposite type from the Subset group.These functions conversely filter and selects table rows in several ways.